
Comprendre le cycle de vie de l’éditeur de bloc

Table des matières
- Contenu sauvegardé
Source de vérité - Analyse des attributs
Basé sur les commentaires HTMLwp.blocks.parse( post.content.raw ) - État du document
Représentation d’un contenu sous forme d’une liste de blocs - Bloc
Composants / balises
Block API - Éditeur visuel
Rendu du contenu
Aperçu - Édition
Manipulation des blocs et de leur interface - État du document
Représentation d’un document sous forme d’une liste de blocs - Sérialisation
Préparer la données à être sauvegardéewp.blocks.serialize( blocks ) - Contenu sauvegardé
Source de vérité
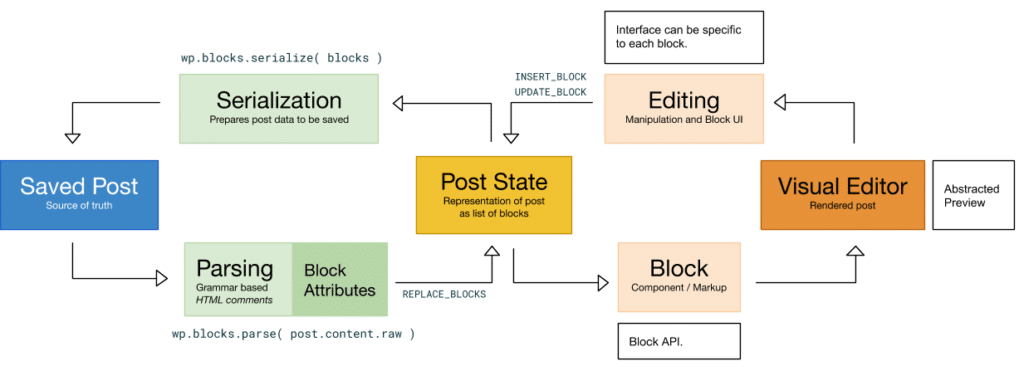
Il existe le schéma officiel ci-contre pour décrire le fonctionnement de Gutenberg mais peut-être qu’il reste des zones d’ombre dans votre compréhension.
L’objectif de cette leçon est de démystifier le fonctionnement de Gutenberg et rendre accessible les méandres de l’éditeur de WordPress.
Découvrons ensemble, le cycle de vie de l’éditeur de WordPress :
Le contenu sauvegardé dans la base de données est la source de vérité
Comme il faut bien un coupable, on a décidé que ce serait la base de données ! Voilà c’est tout.
Plus sérieusement vous l’avez compris tout s’articule autour de cette BDD, qui sert de mémoire à WordPress, donc c’est assez logique que le point de départ (comme le point d’arrivée) se trouve ici.
Si vous avez écrit un paragraphe dans votre article ou votre page, vous vous retrouverez avec ce type de contenu dans la base de données :
<!-- wp:paragraph -->
<p>Cras justo odio, dapibus ac facilisis in, egestas eget quam.</p>
<!-- /wp:paragraph -->On peut identifier des commentaires HTML <!-- wp:paragraph --> et <!-- /wp:paragraph --> qui viennent englober une balise HTML on ne peut plus classique <p>Cras justo odio, dapibus ac facilisis in, egestas eget quam.</p>, un paragraphe.
Ils servent en réalité à délimiter chaque bloc.
Si on continue de décomposer, vous voyez que le commentaire n’est rien d’autre que le nom du bloc qu’on a utilisé. Un identifiant qui permet à Gutenberg de comprendre de quel bloc il s’agit.
Ensuite, Gutenberg analyse les commentaires HTML
Ça tombe bien, on a dit que le contenu qu’on récupère de la base de données contient ces commentaires pour chaque bloc.
À ce moment là de la partie, Gutenberg prends en considération ces commentaires et avec une fonction magique wp.blocks.parse( post.content.raw ), il les convertit dans un format de bloc que l’éditeur pourra exploiter par la suite.
Ce fameux post.content.raw n’est rien d’autre que le contenu brut de la BDD c’est celui qui est renvoyé par l’API REST de WordPress. Plus de mystère maintenant, vous savez que l’éditeur de bloc utilise l’API de WordPress pour récupérer le contenu d’un document.
Mais, parce qu’il y a un mais, ces commentaires sont parfois bien plus riches que le simple nom du bloc utilisé. Si je rajoute des options d’alignement ou des couleurs à mon bloc paragraphe, le contenu sauvegardé se transforme en quelque chose de ce genre là :
<!-- wp:paragraph {"align":"center","backgroundColor":"blue"} -->
<p class="has-text-align-center has-blue-background-color has-background">Cras justo odio, <strong>dapibus</strong> ac facilisis in, egestas eget quam.</p>
<!-- /wp:paragraph -->Vous voyez dans la 1ère partie du commentaire on se retrouve avec du JSON pour décrire les différentes options qu’on a cochées : {"align":"center","backgroundColor":"blue"}
Encore une fois, comme on est en train d’analyser ces commentaires c’est grâce à cet objet JavaScript que l’éditeur va pouvoir réactiver les options que vous aviez cochées avant d’enregistrer votre contenu.
Dans mon cas, l’option « Aligner le texte au centre » et la couleur de fond qui correspond au slug « blue ». Petite parenthèse, c’est au moment où vous personnalisez la palette de couleur que vous choisissez ce slug.
Vous vous en doutez sûrement mais ces commentaires sont enregistrés dans la BDD de WordPress mais n’ont pas vocation à être affiché coté front-end, ils servent uniquement à Gutenberg pour retrouver ses petits.
L’éditeur sauvegarde temporairement la liste de blocs dans un state de React.js
De cette analyse de commentaires l’éditeur extrait une liste de blocs. Avant de pouvoir l’afficher sous forme d’éléments manipulables dans l’interface Gutenberg, on stocke cette liste de blocs dans un « state ».
Cette notion de « state » ou d’état est commune pour les personnes qui code déjà avec React.js, mais ne l’est pas forcément pour tout le monde. Il s’agit en réalité d’une représentation à un instant T d’un système, il est voué à évoluer dans le temps, c’est à dire qu’au fur et à mesure que mon contenu s’étoffe cet état se met à jour avec la liste actuelle des blocs qui composent ma page. C’est vraiment pas plus compliqué désolé…
Revenons à nos moutons, que contient en détail cet état de mon document ?
Comme l’éditeur s’est chargé en amont de traduire les commentaires en données exploitables en JavaScript il est temps de stocker le résultat de cette traduction.
Depuis la console de votre navigateur vous pouvez taper :
wp.data.select( 'core/block-editor' ).getBlocks()Vous obtiendrez alors un truc du genre :
[{…}, {…}, {…}]À première vue un tableau d’objet. Jusque là ça parait logique et sans même dérouler le contenu de chaque objet on peut vite supposer qu’il s’agit du détail de chaque bloc. Creusons ça ensemble.
Si j’ouvre l’objet qui correspond à ce bloc paragraphe en particulier, voici ce que j’obtiens :
{
attributes: {content: "Si j'ouvre l'objet qui correspond à ce bloc paragraphe en particulier, voici ce que j'obtiens :", dropCap: false}
clientId: "6603ac4d-3629-494f-9aad-88171c58413c"
innerBlocks: []
isValid: true
name: "core/paragraph"
}Voici les propriétés qu’on y retrouve :
attributes: les attributs sont propres à chaque bloc et permettent de sauvegarder dans la base de données des réglages, ou des spécificités intrinsèques au bon fonctionnement du bloc que l’on utilise ;clientId: il s’agit d’un identifiant unique pour différencier 2 blocs qui auraient potentiellement le même contenu, les mêmes réglages, etc ;innerBlocks: dans le cas ou le bloc est en capacité d’en accueillir d’autres, par exemple un groupe, une colonne, un media & texte, dans cette propriétéinnerBlocksse retrouve la liste des blocs qu’il contient (sous forme d’objet JavaScript comme celui-ci) ;isValid: cette propriété définit si le bloc est « compréhensible » par l’éditeur en vue de l’afficher ou de le sauvegarder par la suite, Gutenberg s’appuie aussi dessus pour gérer l’obsolescence des blocs (dépréciation de versions antérieures, améliorations fonctionnelles) ;name: correspond au nom du bloc, on le retrouve entre autres dans les commentaires HTML qui sont sauvegardés dans la base de données.
Rendre les blocs dans l’éditeur visuel
Et bien tôt ou tard il va bien falloir charger l’interface de l’éditeur sinon ça va être compliquer de jouer avec.
Être capable de manipuler les blocs
Une fois l’interface prête à accueillir notre contenu et les blocs traduit en objet JavaScript il ne reste plus qu’à les convertir en HTML pour qu’il soit compris par le navigateur et qu’il s’affiche. Pour qu’on puisse les utiliser quoi…
Comment me direz-vous ? On y vient !
Lorsqu’on créé un bloc Gutenberg, il est en réalité scinder en 2 : une partie qui sera rendue dans l’éditeur que l’on appelle edit et une autre uniquement affiché en front que l’on appelle save.
À partir du nom du bloc que Gutenberg est capable de récupérer la partie edit et c’est à ce moment précis que l’éditeur sait quels attributs sont utilisés, quelle(s) balise(s) il doit afficher, etc. La structure et le comportement du bloc quoi…
Les attributs sont restitués sous forme de réglages dans l’interface utilisateur. Et par extension, le markup HTML utilisé dans le bloc est ajusté en fonction des réglages : des classes en plus ou en moins pour contrôler le style voire même des balises qui se rajoutent ou s’enlèvent si l’on active ou désactive certaines options.
Un exemple sera plus parlant.
Admettons qu’il existe une option « Slider » sur le bloc galerie d’images. On comprend naturellement qu’à l’activation de cette option apparaîtrait par exemple les boutons suivant et précédent pour naviguer entre les images. Ce serait du markup HTML généré uniquement dans le cas ou l’option « Slider » serait cochée.
Si vous avez bien suivi jusque là, vous comprenez que l’interface peut être différente en fonction de la logique métier propre à chaque bloc. Les attributs peuvent varier et donc les interactions rattachées à chaque bloc aussi.
En résumé
Gutenberg parse le contenu, grâce aux commentaires HTML qui les délimite, en une liste de blocs stockée en mémoire. Chaque modification de contenu, paramétrage de bloc ou changements de manière générale dans l’éditeur actualise cette liste de blocs.
Cette liste de blocs est de nouveau convertit en HTML (avec les commentaires qui délimite chaque bloc) pour être sauvegardé dans post_content par la suite.